Adding Parallelization to C0
By Joshua Nichols (joshuani) and Lucca Rodrigues (luccar)
1 Summary
We designed and implemented a compiler for a domain-specific language (DSL) that extends C0, CMU's pedagogical subset of C, with the primitives necessary for shared-memory parallel programming: first-class function pointers, void* polymorphic pointers, explicit type casts, and Foreign Function Interface (FFI) bindings to the POSIX pthreads API. The compiler is written in Rust, targets LLVM IR, and has a standard library including parallel map and reduce. We implemented the VLSI wire routing solver from 15-418 Assignment 3 in both C++ and our new language, demonstrating comparable performance between our language's capabilities and the standard OpenMP library used in C++.
2 Background
2.1 The C0 Language
Modern computational hardware is explicitly designed to be parallel, with multi-core processors and Single Instruction, Multiple Data (SIMD) execution units implemented to achieve significant speedups. However, the C0 imperative programming language (a memory safe subset of C) is strictly sequential by design. Because C0 allows for memory operations and mutable state, it is extremely difficult for a compiler to automatically determine which sections of code can be parallelized, resulting in incorrect behavior if optimizations are overly aggressive.
To avoid these issues, modern languages fall on the spectrum between declarative programming and granular imperative programming. The first approach is pure functional programming, where programmers specify the logic of computation without specifying its control flow. The second is providing low-level control-flow management to the user via thread spawning and synchronization, such as pthreads, which can achieve high performance but suffers from being difficult to develop code in, and offers few guarantees about safety and correctness.
2.2 Language Modifications
This project proposes a middle ground between the two approaches: a simple set of extensions to the C0 language to provide high-level parallel primitives. By introducing a structured set of abstractions that allows declarative computation without explicitly managing threads or synchronization, the compiler can guarantee safe execution. The objective of this approach is to keep the imperative structure of C0 while providing a safe framework for achieving high-performance code.
To add parallel programming features to C0 without requiring unsafe thread management, we added several extensions to the language:
- First-class function closures: Lambda expressions which use syntax similar to Rust closures:
|x: int| -> void ...that capture variables from the current scope. Closures are used to pass tasks to worker threads. - Foreign function interface: A foreign function interface which allows C0 to call native system POSIX threads.
- Standard library: A standard library with common parallel algorithms implemented in C0 for users to call.
2.3 The Wire Routing Benchmark
The application we parallelized as a benchmark is a wire-routing solver for VLSI-layout optimization, which was the focus of Assignments 3 and 4. Given a grid with rows and columns, and a set of wires, the objective is to minimize the sum-of-squares equation:
The optimization algorithm is a brute-force simulated annealing approach which iterates through the set of wires, computing the locally optimal path for each wire.
3 Approach
3.1 Compiler Architecture
The compiler is written in Rust and organised as an eleven-crate Cargo workspace. The source code is translated through three distinct intermediate representations before finally being converted into the LLVM IR.
C0 Source
│ parse (Chumsky)
▼
AST
│ ast_lower (closure lowering, name resolution)
▼
HIR
│ typecheck + hir_lower (CFG construction)
▼
MIR / CFG
│ llvm (Inkwell / LLVM 20, O3)
▼
Object File (.o)
│ clang (linker)
▼
Native Executable
Figure 1: Compilation pipeline. IR stages are shown above; pass names and the key transformation each performs are annotated on the arrows.
-
AST: The Chumsky parser combinator produces a
TopLevelenum covering function declarations and definitions, struct declarations, typedefs, and lambda expressions. -
HIR: The HIR desugars typedefs, resolves identifiers to stable numeric indices, and assigns every expression and statement a typed index-vector ID (
ExprId,StmtId,LocalId). Lambda-lifting is performed to convert closure literals into top-level function definitions with explicit capture parameters. -
MIR: A control-flow graph (CFG) in three-address-code (TAC) style. Each basic block is a sequence of
Statementsterminated by one ofGoto,Switch,Call,Return, orAbort. Assignments target aPlace(local + projection list: field access, array index, dereference) and source anRvalue. -
LLVM: The
llvmcrate uses Inkwell to build a module, forward-declare all structs and functions, then walk the MIR CFG and emit LLVM IR basic blocks one-to-one. After emission we apply LLVM's full O3 pass pipeline and emit a native object file targeting the host CPU. The top-level driver invokesclangto link against any libraries.
3.2 Closures
Closures were the most complex compiler feature we implemented, and they are used to pass arguments to worker threads. A closure expression |x: T| -> U { body } is lowered as follows.
The compiler generates a unique struct __ClosureN whose first field is always the function pointer __call, followed by one field per captured variable:
struct __Closure7 {
__call: fn(void*) -> void, // always at offset 0
wires: Wire**,
dim_x: int,
// ...
}
Figure 2: Example generated closure struct for a worker that captures wires and dim_x.
Placing __call at field offset 0 is essential, which allows any closure pointer to be safely cast as void* to extract the function pointer without knowing the specific closure type.
The generated function for each closure takes void* as its first self argument to be compatible with OS thread callbacks of type fn(*const c_void). At the top of the closure body, the compiler emits a cast:
let __self = __env as __Closure7*;
let dim_x = __self->dim_x; // extract captured arguments
Figure 3: Extracting captured arguments at the top of a generated closure body.
When a closure is called, the compiler passes the closure pointer, cast to void*, as the first argument. This allows any || -> void closure to be handed directly to thread_spawn without any additional work.
3.3 Foreign Function Interface
We added the extern keyword to specify externally defined functions for the FFI. The compiler tells LLVM to trust those functions exist without being explicitly defined, and they are only later added during the linking phase.
An external function declaration uses the extern keyword followed by a function declaration with no body:
extern fn pthread_create(thread: void*, attr: void*, start_routine: fn(void*) -> void*, arg: void*) -> int;
extern fn pthread_join(thread: void*, retval: void*) -> int;
Figure 4: Using FFI to call native pthreads.
The AST stores external function declarations as ExternFn, containing only the function name, argument types, and return type. No body is stored, which means typechecking is not performed and the function is assumed to be defined correctly elsewhere.
3.4 Standard Library
The standard library is written entirely in C0 on top of the pthreads FFI described above. It is organised into three layers of increasing abstraction: raw thread primitives, common parallel algorithms, and a thread-pool runtime.
Raw thread primitives. The lowest layer of abstraction wraps pthread_create and pthread_join behind two functions with more conducive types for writing code in C0:
fn thread_spawn(f: fn(void*) -> void*, arg: void*) -> void*;
fn thread_join(t: void*) -> void;
Figure 5: Low-level thread primitives. thread_spawn returns an opaque thread handle; thread_join blocks until the thread completes.
These are thin wrappers which only serve to help the type system. thread_spawn allocates a pthread_t on the heap, calls pthread_create, and returns the pointer as a void* handle. thread_join dereferences the handle and calls pthread_join. The heap allocation is necessary because C0 has no stack-allocated values.
Parallel algorithms. Built on top of the raw primitives, par_map and par_reduce provide a high-level interface that hides thread management from the user:
| Function | Description |
|---|---|
thread_spawn(f, arg) | Spawn one OS thread executing closure f(arg) |
thread_join(t) | Block until thread t completes |
par_map(f, a, n) | Apply f to a[0..n] in parallel |
par_reduce(f, a, n) | Parallel reduction over a[0..n] |
Table 1: Parallel standard-library functions.
Both functions split the input array into equal-sized chunks, spawn one thread per chunk, and join all threads before returning. Each thread is passed a closure that captures its slice bounds and a pointer into the shared array, so no additional synchronization is needed.
Thread-pool runtime. Spawning a new OS thread for each individual task introduces overhead from stack allocation and kernel scheduling. For workloads with many small granular tasks, this overhead can outweigh the benefit of parallel computation. We implemented a thread pool entirely in C0:
let p: pool_t = pool_create(8); // 8 persistent worker threads
pool_submit(p, || -> void { process(item); });
pool_wait(p); // barrier: wait for all tasks
Figure 6: Thread-pool API. Workers are created once and reused across submissions.
pool_create spawns a fixed number of worker threads that operate on a central task queue. pool_submit appends a closure to the queue. Worker threads request tasks by atomically incrementing a shared head index, which provides dynamic load balancing. pool_wait blocks until the queue is empty and all tasks have been completed.
4 Results
4.1 Experimental Setup
We ran benchmarks on an Apple Silicon M3 processor with 8 cores and 18 GB of RAM. The C0 was compiled using our compiler, which used LLVM O3 optimizations, while the C++ code was compiled using clang O3 optimizations. The test input file for the VLSI wire routing problem was medium_wires.txt. We ran 5 iterations of simulated annealing swept over thread counts in . Speedup is computed relative to each program's single core computation time.
4.2 Parallel Speedup
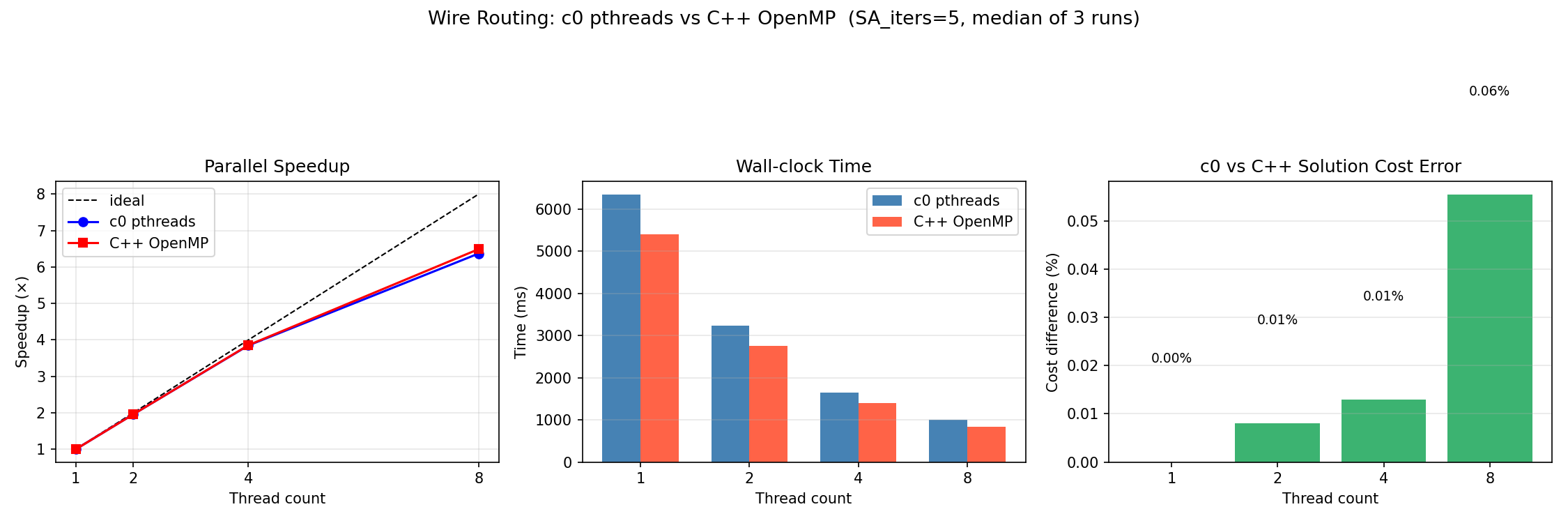
Figure 7: Wire routing benchmark — C0 pthreads vs. C++ OpenMP. SA iters=5, median of 3 runs. Left: speedup relative to each implementation's own 1-thread baseline. Center: wall-clock time. Right: solution cost difference between implementations.
| Threads | C0 (ms) | C++ (ms) | C0 speedup | C++ speedup | Cost err |
|---|---|---|---|---|---|
| 1 | ≈6300 | ≈5400 | 1.00× | 1.00× | 0.00% |
| 2 | ≈3300 | ≈2800 | 1.91× | 1.93× | 0.01% |
| 4 | ≈1600 | ≈1400 | 3.94× | 3.86× | 0.01% |
| 8 | ≈1000 | ≈850 | 6.30× | 6.35× | 0.06% |
Table 2: Wire routing benchmark — C0 pthreads vs. C++ OpenMP. SA iters=5, median of 3 runs.
4.3 Speedup Analysis
Both implementations closely match the ideal linear-speedup line through four threads and deviate from ideal behavior at eight threads. The C0 implementation achieves nearly the same speedup as the C++ OpenMP implementation at every thread count, with a largest deviation of less than 0.2× across all measurements.
At one thread the C0 binary is approximately 17% slower than the C++ binary. We identified several contributing factors to this behavior:
-
Memory layout: In C0, memory is always allocated on the heap, unlike C++ which allows stack allocation. This leads to segmented behavior with worse memory locality behavior, which was confirmed using
perfand cache measurements. -
Virtual function pointers: In our compiler, higher order functions are implemented using virtual function calls with function pointers. This can introduce overhead when virtual function calls are being made repeatedly, which is quite common in map and reduce algorithms. We could resolve the issue by implementing function devirtualization in our compiler's lowest level IR, since we noticed LLVM is unable to devirtualize calls in some occasions. We researched this issue and found the
rustccompiler faced similar issues where LLVM could not fully optimize generated code, and they resolved this by implementing optimizations such as inlining and other across-function algorithms.
4.4 Compiler Correctness
In addition to the wire-routing benchmark, the compiler is verified against an automated suite of unit tests covering arithmetic, control flow, heap allocation, struct field access, generic structs, first-class functions, closures with captures, and closure-based higher-order functions. We implemented the automated testing suite using Rust unit tests, unlike the previous test suite used in 15-411 compiler design. All tests produce identical results to the expected output, giving us confidence that the full pipeline is correct.
5 Work Distribution
| Joshua Nichols | Lucca Rodrigues |
|---|---|
| Compiler pipeline design and architecture | Wire-routing benchmark application (C0 source) |
Parser (parse crate, Chumsky integration) | C++ OpenMP reference implementation |
| AST, HIR, MIR data structures | Benchmark harness (benchmark.py) and result analysis |
Closure lowering and lambda lifting (ast_lower) | Atomic operations in runtime library |
LLVM code generation (llvm crate using inkwell) | thread_spawn/thread_join wrappers in runtime |
| Generic structs/functions, and type inference | Testing and debugging C0 vs C++ code |
Table 3: Work performed by each partner. Credit distribution: 50% / 50%.
References
- Joshua Barretto et al. Chumsky: A Parser Combinator Library for Rust. 2021.
- Daniel Cunningham et al. Inkwell: It's a New Kind of Wrapper for Exposing LLVM Safely. 2018.
- IEEE and The Open Group. The Open Group Base Specifications Issue 7, 2018 Edition: Threads. Tech. rep. IEEE Std 1003.1-2017. IEEE, 2018.